Special considerations for demes models#
Consider the following demographic model:
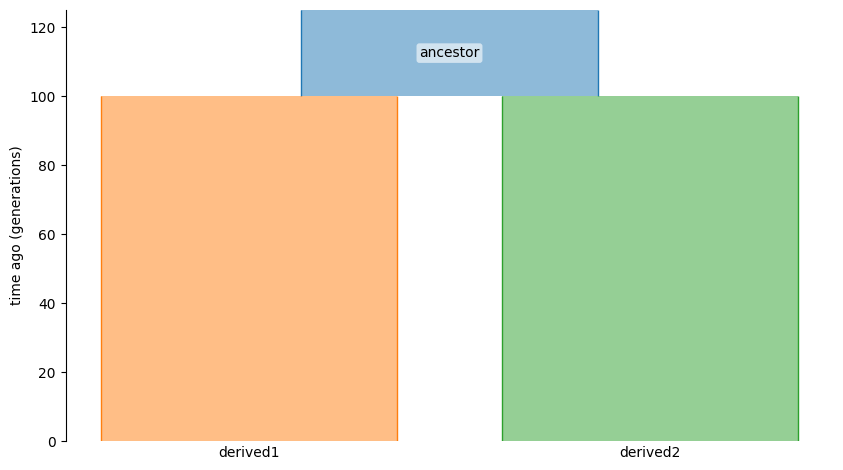
This model has three demes. These demes will have integer labels 0, 1, and 2 according to the order that they are defined in the demes graph. This type of model is called a “split” – the ancestral deme splits into two derived.
This setup is convenient because nodes in the output will be labelled by the deme (0, 1, 2 in this case).
However, you may need to think a bit harder when modeling effect sizes varying across demes.
For example, if you want the effect sizes in derived1 to be identical to those in ancestor, but different from those in derived2, what do you do?
The answer is to define a correlation matrix for three demes where demes 0 and 1 have perfectly-correlated effect sizes.
See here for details.
An alternative is to define the model as a branch model involving only two demes:
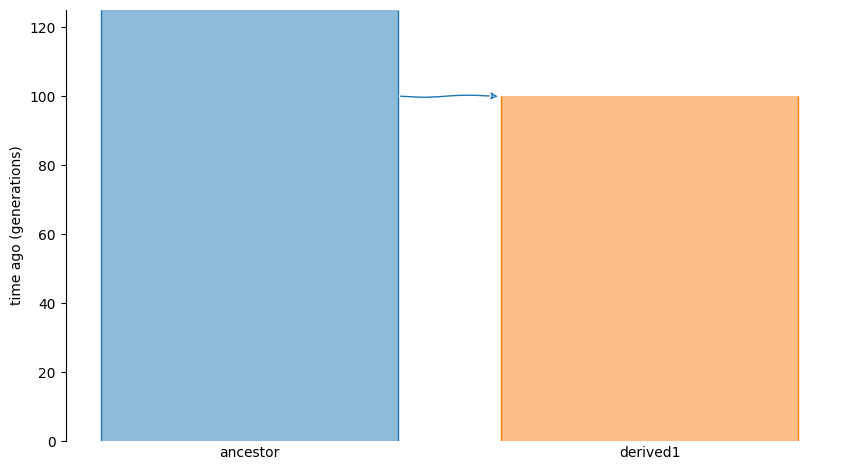
The branch model can be simpler to set up as you only need to consider how effect sizes vary between the ancestral and derived environments. The cost is that you lose information at the node level about which deme a mutation maps to, etc..
See here for more on split vs branch models using demes.